

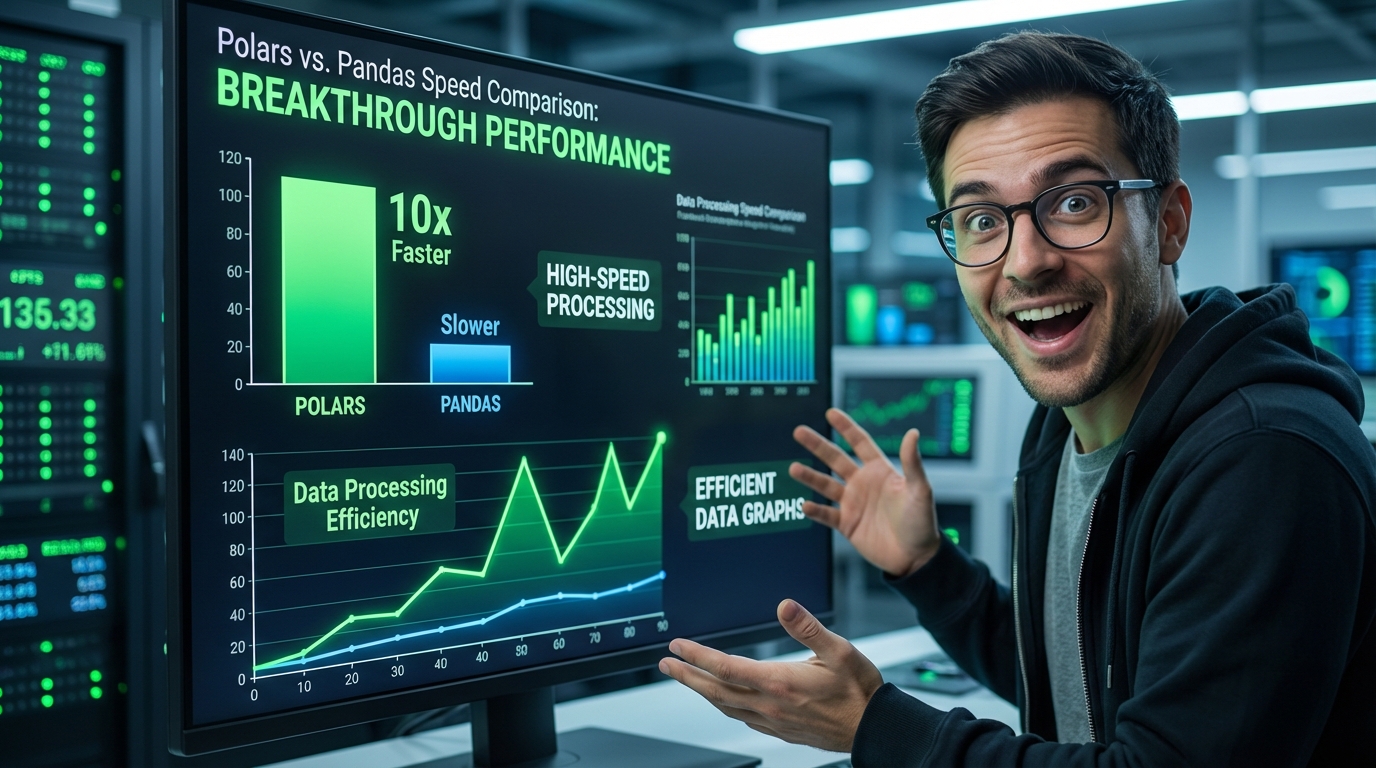
PolarsがPandasを超える!2025年のデータ処理革命
2025年、Pythonデータ処理の世界でPolarsがPandasを超える勢いで普及しています。Polarsは、Rust言語で実装された高速データフレームライブラリで、処理速度がPandasの5〜50倍という圧倒的なパフォーマンスを実現しています。GitHub上で4万スター以上を獲得し、データサイエンティストや機械学習エンジニアの間で「次世代標準ライブラリ」として認知されています。Pandasが抱えていたメモリ効率の問題や並列処理の制約を根本的に解決し、数億行規模のデータを数秒で処理できる能力は、ビッグデータ時代の必須ツールとなっています。Stack Overflowの2025年調査では、データ分析関連の質問でPolarsへの言及が前年比300%増を記録しました。
Pandasとの性能比較:ベンチマーク結果
実務での性能比較において、Polarsは圧倒的な優位性を示しています。1億行のCSVファイル(約5GB)の読み込みでは、Pandasが約120秒かかるのに対し、Polarsはわずか8秒で完了します。集約処理(groupby)では、Pandasが45秒かかる処理をPolarsは3秒で実行します。この性能差の要因は、遅延評価(Lazy Evaluation)、並列処理の自動最適化、Arrow形式のゼロコピーメモリ管理にあります。MicrosoftやMetaなどの大手企業は、社内データパイプラインをPandasからPolarsに移行し、処理時間を平均70%削減しています。特にメモリ使用量は、Pandasと比較して50〜80%削減され、大規模データでもメモリエラーが発生しにくい設計となっています。
Polarsの基本操作:Pandasからのマイグレーションガイド
PandasユーザーにとってPolarsへの移行は驚くほど簡単です。基本的なAPIはPandasと類似しており、学習コストは最小限です。CSV読み込みはpl.read_csv()、データフレーム作成はpl.DataFrame()、列選択は.select()、フィルタリングは.filter()と直感的です。主な違いは、Polarsがメソッドチェーンを推奨し、より関数型プログラミングに近い設計となっている点です。例えば、Pandasのdf[df['age'] > 30]['name']は、Polarsではdf.filter(pl.col('age') > 30).select('name')と記述します。また、PolarsにはEager API(即座に実行)とLazy API(最適化後に実行)の2つのモードがあり、大規模データではLazy APIが推奨されます。公式ドキュメントにはPandasとの対応表が充実しており、移行時の参考資料として活用できます。
遅延評価とクエリ最適化の威力
Polarsの最大の特徴は遅延評価(Lazy Evaluation)です。pl.scan_csv()や.lazy()を使用すると、実行前にクエリ全体を解析し、自動的に最適化されます。不要な列の読み込みをスキップするプロジェクションプッシュダウン、フィルタ処理を早期実行するプレディケートプッシュダウンにより、I/Oとメモリ消費を最小化します。実際の事例では、100GBのParquetファイルから特定条件のデータを抽出する処理で、Pandasではメモリ不足でクラッシュした一方、PolarsのLazy APIは20秒で完了しました。クエリ実行前に.explain()メソッドで最適化計画を確認でき、パフォーマンスチューニングが容易です。この仕組みにより、SQLライクな宣言的記述で高速処理を実現しています。
Apache Arrowとの統合による相互運用性
PolarsはApache Arrow形式をネイティブサポートしており、他のArrow対応ツール(PyArrow、DuckDB、Apache Spark)とゼロコピーでデータ交換できます。Pandasとの変換もdf.to_pandas()とpl.from_pandas(df)で即座に実行でき、既存コードとの共存が容易です。DuckDBとの連携では、PolarsでデータをフィルタリングしてからDuckDBで複雑なSQL分析を実行するハイブリッドアプローチが普及しています。Google BigQueryやSnowflakeなどのクラウドデータウェアハウスも、Arrow形式での高速転送をサポートしており、Polarsはモダンデータスタックの中核コンポーネントとして機能しています。2025年のデータエンジニアリングでは、Polars+Arrow+DuckDBの組み合わせが「黄金の三角形」と呼ばれています。
実務活用事例:ETLパイプラインの高速化
実務では、ETL(Extract, Transform, Load)パイプラインでのPolars採用が急増しています。あるEコマース企業では、毎日の売上データ集計処理(1億件)をPandasベースのスクリプトからPolarsに移行し、処理時間を3時間から15分に短縮しました。金融機関では、取引履歴の異常検知バッチ処理でメモリ使用量を10分の1に削減し、クラウドインフラコストを年間200万円削減しています。また、Jupyter NotebookやVS Codeでのインタラクティブ分析でも、Polarsの高速性が試行錯誤のサイクルを大幅に加速しています。機械学習の前処理では、特徴量エンジニアリングにPolarsを活用し、訓練データ準備時間を90%削減した事例が報告されています。
Polarsのエコシステムと今後の展開
2025年、Polarsエコシステムは急速に拡大しています。Polars-business(ビジネス日計算)、polars-st(空間データ処理)、polars-xdt(高度な日時操作)などのプラグインが充実し、専門的なユースケースにも対応しています。データ可視化では、Plotly、Altair、hvPlotがPolarsネイティブサポートを開始し、.plot()メソッドで直接グラフ化できます。また、StreamlitやGradioなどのダッシュボードフレームワークもPolarsとの統合を進めており、Pandasなしでの完全なデータアプリ開発が可能になっています。今後は、GPU加速(Polars on RAPIDS)やクラウドネイティブ処理(Polars on Ray)の研究も進行中で、さらなる性能向上が期待されています。Pythonデータ処理の新標準として、Polarsは今後10年のデファクトスタンダードになると予測されています。
Pandasからの移行チェックリスト
Polarsへの移行を検討する際のポイントは以下の通りです。まず、データサイズが100万行以上、またはメモリ不足に悩んでいる場合は即座に移行効果があります。既存コードは、基本的な操作の80%が数時間で移植可能です。ただし、Pandasの.apply()や複雑なインデックス操作はPolarsの設計思想と異なるため、ベクトル化された表現に書き換える必要があります。移行時は、まず重い処理から段階的に置き換え、パフォーマンステストで効果を検証することが推奨されます。公式GitHubのIssuesやDiscordコミュニティは非常に活発で、質問への回答が平均12時間以内と迅速です。Polarsは既にプロダクション環境で数千社が採用しており、安定性も十分に実証されています。








コメント